Introduction
Stage 2 of this project, will introduce some new concepts and goals. Previously, I created a dummy gcc pass, that simply counts and outputs the number of functions, Basic Blocks (BB), and GIMPLE statements in the code. This pass doesn’t perform any optimizations, or even significant observations, or assortations about the code – it simply outputs some diagnostic lines, to help further our understanding of how it works. By the end of Stage 2, the gcc pass should meet the following requirements:
- Identify functions that have been cloned.
- Assess the clones, and determine if they are “substantially the same”.
- Output an organized diagnostic dump, that indicates which functions we should
PRUNE(the same), which weNOPRUNE.
I will be using the same gcc pass I created in Stage 1, improving it step by step, to achieve the desired outcome. But first, I need to understand what clones are, how they happen, and how we can identify them.
FMV: Function Multiple Versions
For the purposes of this project, the clones I am referring to are not actual cloned lines of code, in the original source. These are actually clones of the same base function (that appears in the original compiled file), that are produced during the compilation process, to optimize the performance of the code in specific conditions, and environments.
Optimizing for Different Architectures – SIMD
The most common scenario, or reason, to create different clones of the same base function, is to optimize for specific architechtures. Different machines have different CPU types, with different assembly instruction sets. This means that in order to optimize the code past a certain point, we have to transition towards machine-specific optimizations.
For example, x86 processors (like the one I use), support SIMD (Single Instruction, Multiple Data), which is a parallel computing technique that allows a simgle instruction to be performed simultanerously, on multiple datapoints.
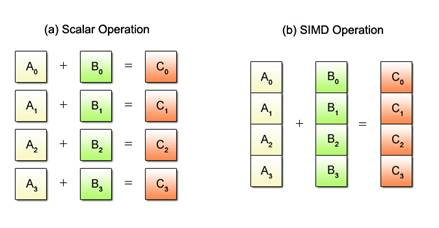
The code version of the same analogy, shows the difference between this common code:
for (int i = 0; i < 4; i++) {
result[i] = a[i] + b[i]; // Add one pair of items at a time
}And a much more simplified version, which acheives the same result, and processes the data in parallel.
result = a + b; // Adds multiple elements in a single operationBut in order to take advantage of this amazing feature, we must differentiate between systems that are able to do this, and systems that cannot. This is why there are often multiple function clones produced, even for a simple function – because on some systems, it can be optimized further.
Compiler Optimization Levels
- There are many optimization levels, which can be specified as flags, allowing to specify the “emphasis” on code performance, binary size, debugging capabilities, and runtime efficiency.
- Example: No optimization, for debugging at
-O0, vs. maximum performance optimization at-O3.
Memory Model Variations
- Different computer architectures implement memory addressing, alignment, and access patterns in fundamentally distinct ways, requiring specialized code to maximize computational efficiency.
- Example: Data processing functions optimized for 32-bit vs. 64-bit memory.
Runtime Environment
- There are many different computing environments: memory constrained embedded systems, parallel computing clusters, each demanding unique performance characteristics.
- Example: RAM-constrained systems require code with minimal memory footprint.
Language and Runtime Support
- Different programming languages manage tasks differently, which requires implementation variations.
- Example: Managing memory with garbage-collected languages (Java), vs. manual memory languages (C, C++).
Managing Multiple Function Versions – Resolver
A resolver is a special function that runs the first time a function is called, and it determines which function variant to use.
It works by checking all the conditions mentioned above, including CPU instructions, available hardware, system architechture and flags specified. Based on this analysis, it selects the most optimized version for the current conditions.
Dynamic Function Resolution
IFUNC (Indirect Function) is the mechanism responsible for thi dynamic function implemenetation selection, at runtime. It allows the resolver to replace the function pointer with the selected implementation, dynamically, at runtime.
Function Pruning
When multiple versions of a function exist, not all of them are unique or necessary. Function pruning is the process of identifying and removing redundant function variants that are “substantially the same.”
What is Considered “Substantially the Same”?
- Two functions that have the same logic, and produce the same output for any input.
- Differences in variable naming shouldn’t affect the decision.
When identifying “same” clones, I will have to ensure that I am ignoring common, small differences, that shouldn’t count. In the more advanced stages, when comparing the logic of the clones, I will ensure that the clones are normalized.
Why Prune Functions?
- Multiple function variants increase binary size
- Redundant variants consume unnecessary memory and compilation resources, adding complexity to the compiled code.
- Pruning can improve the size and performance of the compiled binary, and runtime execution.
How to Identify Substantially Similar Functions
Here are some ways I will be able to check and compare if functions are substantial clones of eachother, and should be pruned (ordered from easy checks, to harder analysis):
- Compare base name – functions with the same base name, are clones of eachother.
- Compare number of Basic Blocks & GIMPLE statements.
- Comparing the logic, line by line.
- Normalizing and hashing the functions, comparing the hashes.
Conclusion & Plan
I defined the goals, the requirements and the logic of how I will proceed to modify my dummy gcc pass, to prune cloned functions that are substantially the same. Now all that’s left is to experiement with the code, and achieve the right result.
Leave a Reply